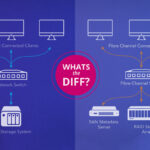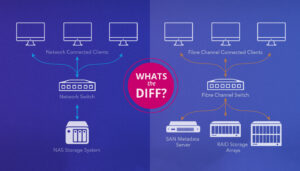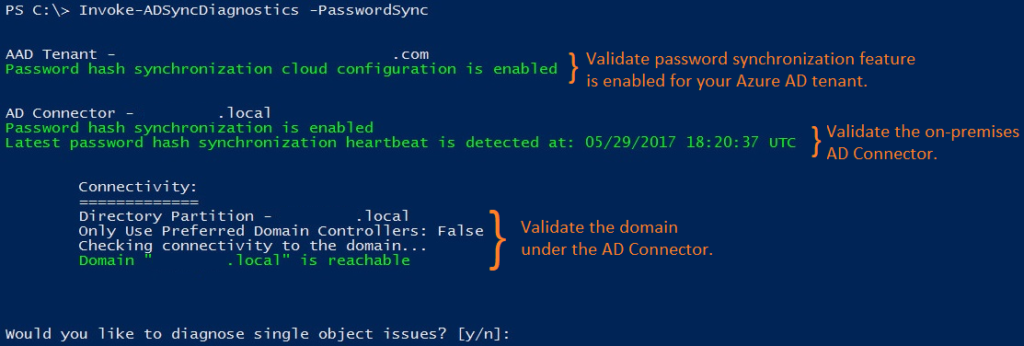
Clusters are critical in distributed systems, but file communication and synchronization issues can disrupt operations, causing inefficiencies or downtime. This guide outlines the most common causes and solutions for such problems.
1. Check Network Connectivity
- Issue: Nodes in the cluster may fail to communicate due to network issues.
- Solution:
- Verify all nodes are properly connected.
- Check firewalls, routers, or network configurations for any blocks.
- Use tools like
ping,traceroute, ortelnetto ensure communication between nodes.
2. Validate Cluster Configuration
- Issue: Misconfigurations in cluster files can lead to sync failures.
- Solution:
- Ensure cluster configuration files are consistent across all nodes.
- Double-check IP addresses, hostnames, and ports in the configuration files.
3. Inspect File Synchronization Tools
- Issue: Sync tools (e.g., rsync, GlusterFS, or other distributed systems) may not work correctly.
- Solution:
- Check logs for synchronization errors.
- Verify that sync services or daemons are running properly on all nodes.
4. Verify File and Directory Permissions
- Issue: Incorrect permissions may block file access or updates.
- Solution:
- Check file and directory permissions to ensure nodes have appropriate read/write access.
- Use
chmodorchowncommands to adjust permissions if needed.
5. Review Cluster Management Logs
- Issue: Errors in the cluster management system may prevent communication or synchronization.
- Solution:
- Inspect logs from tools like Kubernetes, Docker Swarm, or others used in your cluster.
- Common log locations:
/var/log/messages/var/log/syslog- Tool-specific logs (e.g., HDFS logs for Hadoop).
6. Synchronize Node Clocks
- Issue: Time drift between nodes can cause sync issues.
- Solution:
- Use Network Time Protocol (NTP) to ensure synchronized clocks.
- Run commands
ntpdateto check and correct time drift.
7. Check Version Compatibility
- Issue: Incompatible software versions can break cluster functionality.
- Solution:
- Ensure all nodes run compatible versions of the software or tools.
- Upgrade or downgrade as necessary to match the cluster’s requirements.
8. Monitor Disk Space and Inode Availability
- Issue: A node running out of disk space or inodes may stop syncing.
- Solution:
- Check disk usage using commands like
df -h. - Clear unnecessary files or add more storage as needed.
- Check disk usage using commands like
9. Address Network Latency Issues
- Issue: High latency or packet loss can disrupt communication.
- Solution:
- Use tools
iperfto test network speed and latency. - Optimize network routes or consider upgrading hardware for better throughput.
- Use tools
10. Restart Services
- Issue: Temporary glitches in cluster services may cause syncing problems.
- Solution:
- Restart the affected sync or cluster services.
- Reboot nodes if necessary to restore functionality.
Best Practices for Prevention
- Monitoring and Alerts
- Use tools like Prometheus, Grafana, or Nagios to monitor cluster health and receive real-time alerts.
- Documentation and Procedures
- Maintain up-to-date documentation on configurations, troubleshooting steps, and system architecture.
- Automation and Consistency
- Employ configuration management and automation tools for repeatable, error-free deployments.
- Regular Maintenance
- Schedule periodic audits of cluster health, disk usage, and time synchronization.
To find out about our services,
- Contact us.